Markov Chain
We say a Stochastic Process has k-th order Markov property if
And we call an instance of this sequence a Markov chain.
- Random Walk is a simple example of a Markov chain.
Concepts
Transition Kernel
For finite state space , its transition matrix is specified by . This matrix is also called the transition kernel or the Markov matrix; it is a row-stochastic matrix.
For general state space, the transition kernel is a family of measurable functions such that .
We also often use the transition kernel as an operator such that . However, for the matrix , by its definition, we should write instead.
The above definitions are for homogeneous Markov chains, where the transition kernel is independent of time: for all .
Stationary Distribution
A probability distribution is called a stationary (steady/equilibrium) distribution if , or equivalently for discrete cases. If on a Markov chain , we say the chain is in steady-state.
Thm
Finite-space time-homogeneous Markov chains always have a stationary distribution.
This theorem can be proved by various methods:
- This is a corollary of a general theorem on the stationary distribution’s existence.
- Brouwer’s fixed-point theorem.
- Linear Programming approach.
LP approach
A finite-space time-homogeneous Markov chain has a stationary distribution if and only if the following linear program has an unbounded objective function:
This is because if is a stationary distribution, then for any is a feasible solution to the LP, and the objective function is unbounded; if the LP has an unbounded objective function, it must have a feasible solution, which can be normalized to be a stationary distribution.
On the other hand, the LP has an unbounded objective function if and only if its dual is infeasible. The dual is
If the dual is feasible, there exists such that . WLOG, suppose . Then the first row of satisfies
contradicting the constraint.
- For tabular cases, we also know from the fact that the largest eigenvalue of is 1 and the steady distribution is its unit eigenvector.
Transient and Recurrent States
For two states and , we write if there exists a non-zero probability of transitioning from to ; formally, .
A state is called transient if there exists a state such that but . Otherwise, it is called recurrent.
We say two states and communicate if and , and we write . Communicating states form an equivalence class on the set of recurrent states:
-
- Let be any state that (which could be ). Thus . Since is recurrent, . Therefore, .
Therefore, the state space can be partitioned into the set of transient states and the set of communicating classes of recurrent states.
See Recurrence Time for the properties of transient and recurrent states.
Times
Given a state , we define the following times:
- First passage/ hitting/ return time: .
- We set if the minimum doesn’t exist.
- Mean recurrence time: .
- Visit time: .
- Absorption time: .
Irreducibility
We say a Markov chain is irreducible if we can eventually reach any state starting from any other state. That is, the Markov chain has no transient states and has only one recurrent class.
Thm
Periodicity
We define the
- transient probability (or density for continuous cases) from to as . Given a transition matrix , we have ;
- accessible times of state as , which is a non-empty set for recurrent states and is closed under addition: ;
- period of state as .
- All states in the same recurrent class have the same period.
- A recurrent class is called periodic if its period is greater than 1; otherwise, it is called aperiodic.
See Periodicity for the properties of periodic and aperiodic states/ Markov chains.
- We say a kernel is aperiodic if the sequence doesn’t loop between sets of states in a pre-defined pattern.
Ergodicity
We say
- a state is ergodic if it’s recurrent and aperiodic;
- a Markov chain is ergodic if it’s irreducible and all its states are ergodic,
- equivalently, the chain is irreducible and aperiodic.
- For continuous state space, an ergodic chain is also needed to be positive recurrent, i.e., the mean recurrence time of any state is finite. This is automatically satisfied for finite state space.
We have the Mixing Property:
Transclude of mixing-property#^c7829b
Alt Def 1. Sometimes we refer to the ergodicity as the mixing property, i.e., we say a kernel is ergodic if there exists a stationary distribution of states such that for any initial distribution of . For tabular cases, this reads .
- In this case, irreducibility + aperiodicity ⇒ ergodicity.
Alt Def 2. Aligned more closely to the ergodic theory, an ergodic Markov chain is just irreducible. In this sense, the chain is possible to go from any state to any other state in a finite number of steps and every state is visited infinitely often.
Without assuming either irreducibility or aperiodicity, we still have an Ergodic Theorem for chains with a single recurrence class, which relates the time average to the spatial average .
Transclude of ergodic-theorem#^thm
MRP and MDP
POMDP
Model Learning
The most widely used technique to learn a Markov kernel is the Monte Carlo Method, which uses Maximum Likelihood Estimation.
Since each row of has to be a probability distribution, we can show that
Empirically, count how many times we observe a transition from and divide by the total number of transitions from .
Simple Ergodic Model-Based Applications
We present two Markov chain model applications assuming ergodicity and the full knowledge of the kernel (so we can compute the steady distribution).
Ranking
Problem setup
- We construct a Markov chain where each object is a state.
- We encourage transitions from objects that lose to objects that win.
- Transitions only occur between objects that play each other.
- If object A beats object B, there should be a high probability of transitioning from B→A and small probability from A→B.
- The strength of the transition can be linked to the score of the game.
- for each game, the unnormalized probability is updated as , where can be A or B, so we are updating four entries after each game.
- Predicting the “state” (i.e., object) far in the future, we can interpret a more probable state as a better object.
Semi-Supervised Classification
For a Semi-Supervised Learning Classification, we can use a random walk method:
- A “random walker” starts from an unlabeled point and moves around from point to point
- A transition between nearby points has a higher probability
- Distance defined by Euclidean distance, kernels, etc.
- A transition to a labeled point terminates the walk
- We label using the label of the terminal point
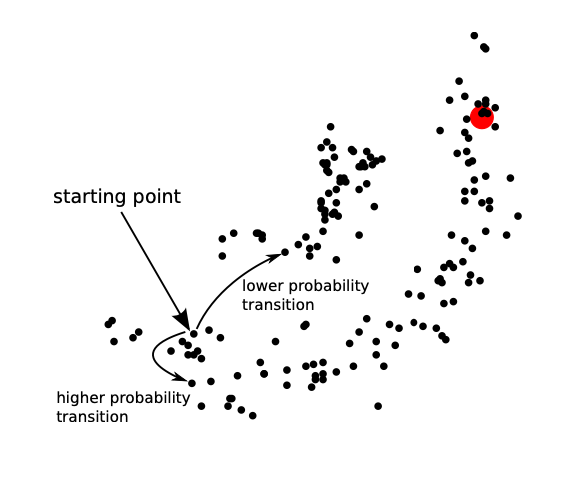
We call the points with pre-defined labels absorbing states because the transition probability from these states to another state is zero. Therefore, this model is not ergodic, indicating the convergence distribution is dependent on the initial state. We arrange in a way that all the absorbing states appear at the bottom right:
Then,
The second equality is from . Then, for any unlabeled data point , we know its classification weight vector is
