Expectation Maximization
Expectation Maximization (EM) algorithm is an iterative algorithm used to estimate the Maximum Likelihood Estimation (MLE) or Maximum a Posteriori (MAP) parameters of a probabilistic model, in the presence of unobserved or missing data.
Imagine we have a hidden (unobserved or missing) random variable , given whose observation the Likelihood is easy to compute or optimize. When only is available, we take the expectation over :
Then, optimizing the RHS gives us the MLE/MAP.
Missing Gaussian Data
For a Gaussian random variable with observed subvector and missing subvector , we can easily find its Maximum Likelihood Estimation for parameters when there is no missing data. Therefore, with the presence of missing data, we have
where and are the sub-vector/sub-matrix of and defined by .
Mixture of Gaussians
For the mixture of two Gaussian distributions and , it can be think of that the random variable first pick a Gaussian distribution with probability , and then sample from the selected Gaussian. Under this interpretation, the hidden variable is the index of the selected Gaussian. Then, , where and .
With the help of this auxiliary variable , the log-likelihood function changed from
which is neither convex nor concave in and , to
which is concave in and .
More often, the Log-Likelihood function, which is a summation instead of a production, is easier to optimize given complete data: . This motivates the EM algorithm.
Objective Justification
Decomposition
Formally, with the help of another random variable and its distribution , we have the following log-likelihood decomposition:
where is the conditional distribution of given and , and is the Cross-Entropy.
Should we maximize or minimize the entropy term in the above decomposition?
Since we want to maximize the log-likelihood, the above decomposition seems to suggest that we should maximize the cross-entropy over . However, it’s important to note that the above equality holds for any . And thus is not a decision variable.
Instead, we notice that
because the KL Divergence is always non-negative. Therefore, we see that when optimizing the log-likelihood over , the increase of the objective will be lower bounded by the increase of the expectation term , which is easier to optimize as it involves the log-likelihood of the complete data . And to make this lower bound tight, we need to minimize the Cross-Entropy/KL Divergence term. By this, any increase in the expectation term leads to the maximum increase in the log-likelihood.
Another reason for minimizing the cross-entropy term is given in Convergence Property.
Lower Bound
We can also use the marginalization/expectation in ^eq-margin for log-likelihood. To do this, we need to introduce an arbitrary distribution for and uses Jensen’s inequality:
Similarly, to make any increase in the expectation term lead to the maximum increase in the log-likelihood, we need the equality to hold, which requires
Algorithm
Justified above, the EM algorithm iteratively minimizes the cross-entropy term and then maximizes the expectation term:
- E-step: Update
and calculate the expectation . 2. M-step: Update
Convergence Property
Generally, EM is not theoretically guaranteed to converge to the Maximum Likelihood Estimation or Maximum a Posteriori. However, it is a monotonic increasing algorithm:
Note that we have two increases in one iteration:
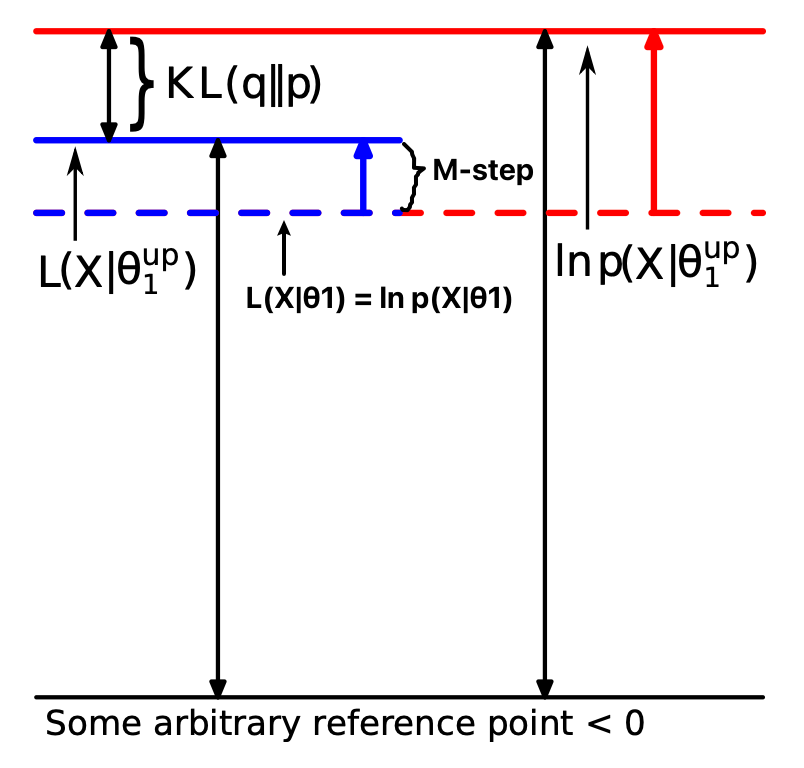 Additionally, the increase in the cross-entropy/KL term is introduced by the update of rather than . And to make any update in lead to an increase in the cross-entropy/KL term, we need to first minimize the cross-entropy/KL term in the E-step. This reasoning is consistent with Objective Justification.
Additionally, the increase in the cross-entropy/KL term is introduced by the update of rather than . And to make any update in lead to an increase in the cross-entropy/KL term, we need to first minimize the cross-entropy/KL term in the E-step. This reasoning is consistent with Objective Justification.
Application: Mixed Gaussian Model
Continuing the mixture of Gaussians example, we see that given the hidden observation , we can easily calculate the log-likelihood maximizer:
Without direct observation, we replace them with expectation:
Setting the distribution of as gives the E-step:
which is larger than 0.5 if is closer to , and smaller than 0.5 if is closer to . Then, the M-step is to maximize the expectation:
Application: Filling Missing Gaussian Data
We now return to the example of missing Gaussian data, to both learn the parameter and fill in the missing data. In this specific problem . And the objective decomposition reads
As we can see, the only difficult part is calculating .
For the E-step, since , by Normal Marginal Distribution from Normal Joint Distribution, we get the conditional parameter of ^q:
For the M-step, we need to maximize the following expectation:
where . Then the maximization gives us
where is with the missing values being replaced by , and is the zeros matrix plus the sub-matrix in the missing dimensions.