M-Estimator
For an Estimation task, one can have different objectives (or metrics). For example, MLE maximizes the likelihood of the estimator, Least Squares minimizes its squared error, and Ridge Regression minimizes the squared error with a penalty term.
M-estimators generalize the above ideas by using a general objective function,
Then, we can define the empirical error: , a.k.a. the criterion function. And an M-Estimator minimizes the empirical error:
- 💡 We can see that M-estimators and Empirical Risk Minimization have the same formulation, one in the context of Estimation and the other in the context of Prediction/Supervised Learning.
Examples
We only need to specify the function to get different M-estimators.
- Maximum Likelihood Estimation: .
- Ordinary Least Squares: .
- Ridge Regression: .
- Median regression: .
- Quantile regression: .
- This loss is also known as the pinball loss.
Properties
In this section, we denote , and
Consistency
By LLN, we know that
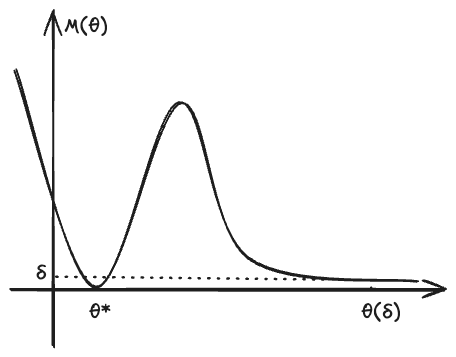
We wonder under what conditions the following is also true
In the function graph of and (see e.g. ^fig-m-graph), the question ask what conditions allow to transfer the convergence of y-axis to that of x-axis.
It turns out that the above consistency holds under two reasonable conditions:
-
Uniform convergence: .
- Some sufficient conditions for uniform convergence:
- Finite VC dimension.
- Finite Rademacher Complexity or Gaussian Complexity.
- Compact and continuous and (in ), and .
- Some sufficient conditions for uniform convergence:
-
Separation: For any ,
- 💡 In words, this condition says that only parameters close to may yield a value of close to the minimum .
Proof of Consistency
By the definition of , we have the critical inequality:
Thus, we have
By the uniform convergence condition,
Then, since no other parameter can yield a value of close to by the separation condition, we know . More specifically, for any , we have
Then, since , we know that . By the arbitrariness of , we get the result.
Consistency of Approximate Estimator
As we can see in the proof, the crucial step is . Therefore, we can replace by any approximate estimator (approximate minimizer of ), and its consistent as long as holds, or equivalently,
Asymptotic Normality
Under some regularity conditions:
- is differentiable at -a.s. (for almost every );
- There exists an function , such that for all in a neighborhood of ;
- is twice differentiable with a non-singular second derivative at , denoted as ;
we have
- ❗️ Note that we do not require is twice differentiable. The twice differentiability of is weaker.
Proof of Asymptotic Normality
The regularity conditions allow the commutation of expectation and derivatives. By definition, minimizes the sample criterion function , and thus is the zero of its derivative. By Taylor expansion,
where is some point between and . By LLN,
By the regularity conditions and the Consistency property,
which is invertible. Thus, by CMT, we have
Finally, since minimizes the population objective , . By CLT,
Slutsky’s Theorem gives
Asymptotic Normality of Quantile Regression
Treating quantile regression as an M-estimator, we verify the above conditions and establish its asymptotic normality. Recall the pinball loss function:
For the first condition, exists if . For any continuous distribution, , so the first condition holds, and .
The second condition also holds:
For the third condition, we have
By integration by parts,
Thus,
We need .
Now we calculate the asymptotic variance. Note that our convergence point is the -th quantile . Plugging it in gives
Finally, we get
Z-Estimator
M-estimators further give rise to Z-Estimators. In many ways, Z-estimators are further generalizations of M-estimators and Moment Estimators, because they solve the zero point of a system. When the function is differentiable, the zero point of its gradient equates to the M-Estimator. Z-estimators also generalize moment estimators, which solve the zero point of the moment equations.